Why some authors are annoyed by data editors
This is the first in an occasional series about what data editors actually do, told through (anonymized, lightly fictionalized) cases from my desk.
Recently I received a replication package that produced a figure much like the one below.
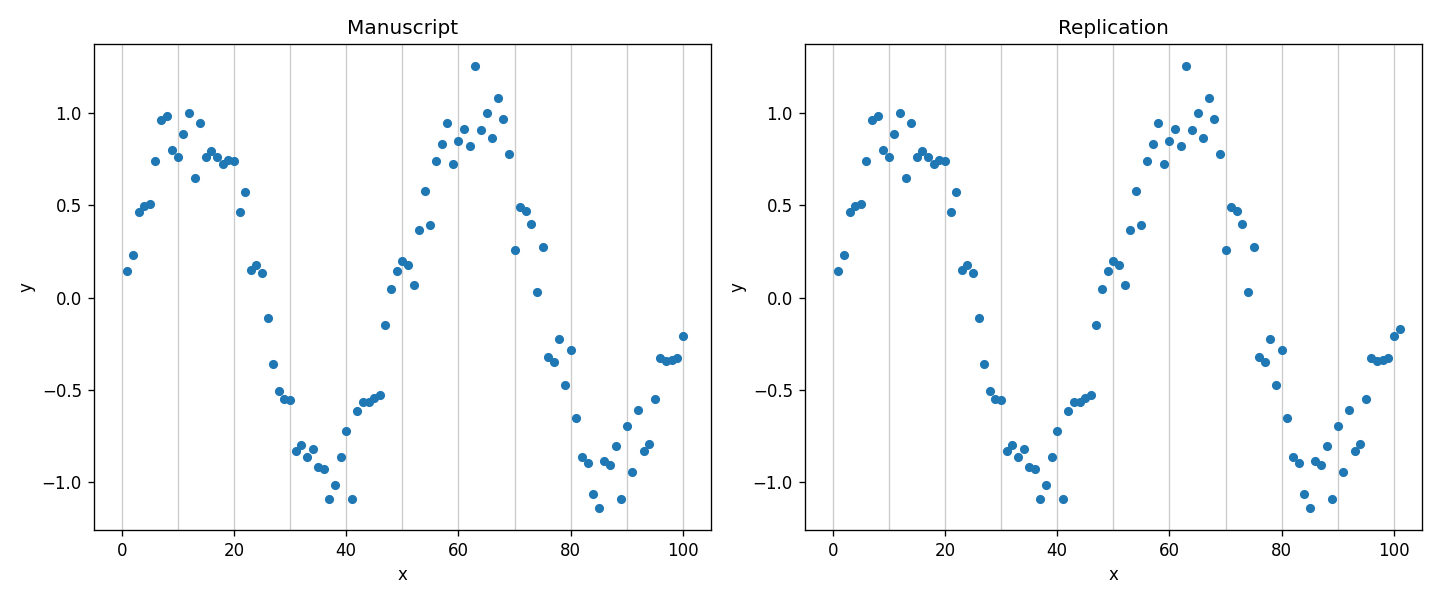
A quick disclaimer: this is not the actual figure. I had Claude draw a stand-in with random data so I’m not revealing anyone’s work. But the substance is exactly the same. Manuscript on the left, replication on the right. Nearly identical.
Notice any difference?
Look closely.
The replication on the right has 101 points. The manuscript on the left has only 100 — it’s missing the dot at x = 101.
I sent the package back and asked the author to do one of two things: either correct the discrepancy so the replication matches the published figure, or ask the managing editor for permission to modify the manuscript so the paper matches the replication.
The author was puzzled, and maybe a little annoyed. (They were, in fact, very nice about it — I may be projecting.) We exchanged a few emails.
“But this is a trivial difference that does not change the message of the paper!”
This is the natural reaction, and it’s a fair one. The two panels clearly convey the same message. Same shape, same story. Who cares about one dot at the edge?
Here’s the thing: I don’t know whether that dot matters, and it’s not my job to decide.
I haven’t read the paper the way the author and the referees have. I have no way of knowing whether the point at x = 101 is incidental, or whether it’s the observation that anchors a claim, flips a sign, or changes a conclusion somewhere downstream. From where I sit, I can’t tell a cosmetic difference from a substantive one — and that’s precisely why it’s not my call to wave it through.
The paper was accepted with a specific figure in it. The replication package produces a different figure. Those two facts can’t both stand unreconciled. Either the code should reproduce what was published, or the published record should be updated — with the editor’s sign-off — to reflect what the code actually does.
Why this isn’t pedantry (even though it feels like it)
I get it. From the outside this looks like nitpicking. I genuinely sympathize — and I’ll admit I find it hard to articulate a clean threshold for which discrepancies are “fine” and which aren’t.
But that difficulty is the whole point. Replication failures are very often built out of exactly these “minor” details: an off-by-one filter, a dropped observation, a silent xlim that clips a point off the edge of a plot. Each one looks trivial in isolation. The trouble is that trivial-looking and inconsequential are not the same thing, and the only honest way to find out which is which is to reconcile the difference rather than assume it away.
If I start drawing the line at “eh, close enough,” I have to defend where that line sits — and there’s no principled place to put it. So the rule is simpler and more defensible: the package should reproduce the paper. Full stop.
And that, dear authors, is why people are sometimes annoyed at their data editors. :)